
Predicting an Election

The first presidential debate of the season is now in the books, and it appears to have led to significant changes in beliefs about the outcome of the November election, and even the outcome of the Democratic National Convention in August.
Here, for instance, is the price path of the Biden contract in the market for the Democratic nominee on PredictIt:

The sharp decline (from 85 to about 62) took place during the debate itself, well before Biden started to face a chorus of calls from supporters to step aside. It has recovered a bit following a more vigorous performance at a campaign rally in North Carolina, but remains below 70.
Meanwhile, the market for the winner of the presidential election moved as follows:

The collapse in the Biden contract price was much larger than the rise in the price of the Trump contract, consistent with the view that someone other than these two candidates could conceivably win.
Now consider model-based forecasts of the election, such as those published by FiveThirtyEight and Silver Bulletin.1 The former model, last updated on June 29, gives Biden a slight edge:
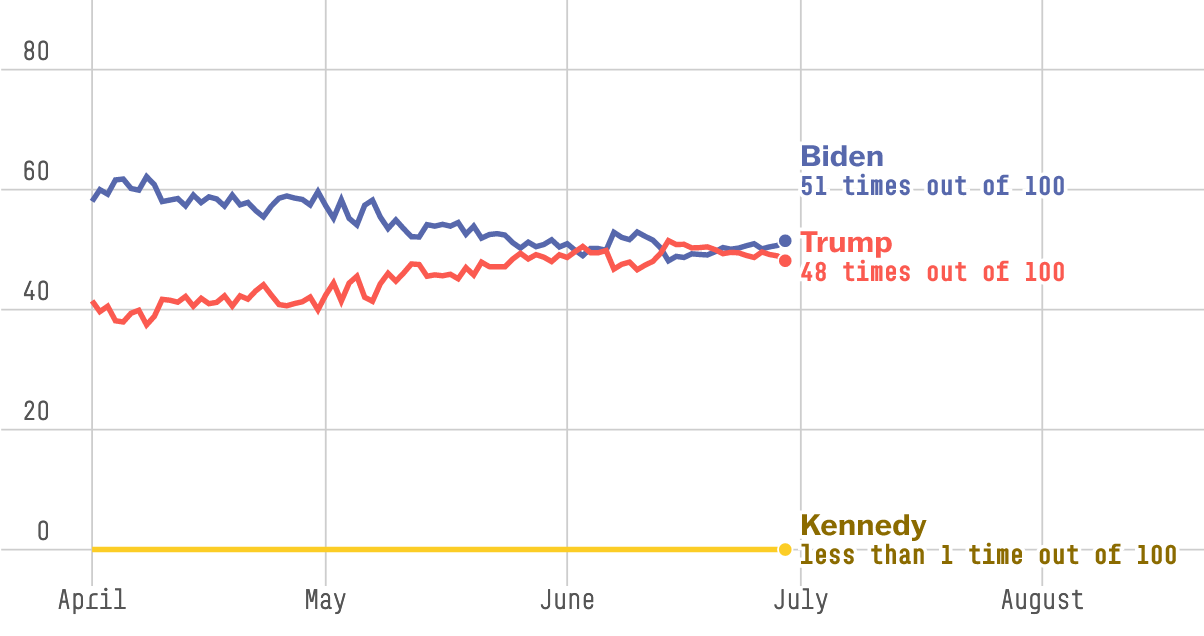
Meanwhile the latter model, last updated on June 27 (before the debate) favors Trump:
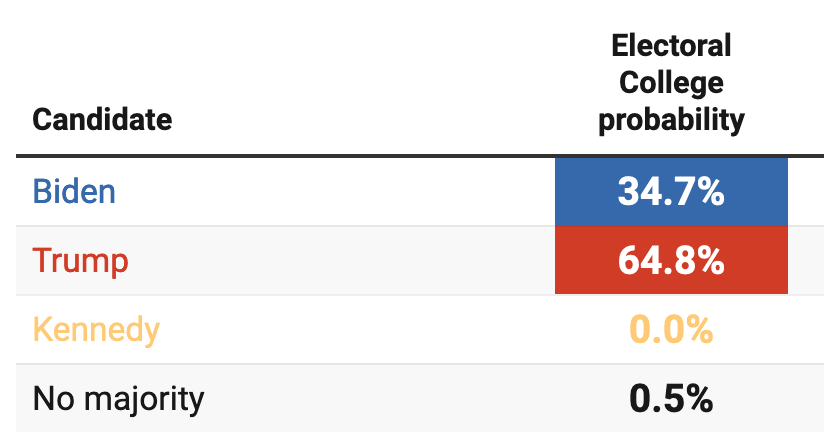
Neither model assigns any probability to victory by a Democratic nominee other than Biden, and it’s not clear how they will be revised if Biden were indeed to step aside.
That is, the models and the markets are sending us very different messages at the moment. It is possible that the variables driving the models will change sharply over the coming days, and bring the model forecasts into alignment with the markets. It is also possible that the markets will be seen to have overreacted, and will snap back towards the model forecasts. Or some combination of the two.
Models are necessarily backward-looking, constructed and calibrated based on historical data. They rely on an assumption that the data generating process is relatively stable over time, so that the past can be a reliable guide to the future.
Markets, in contrast, are fundamentally forward-looking. Any factor that a trader considers to be relevant gets absorbed into prices through their buying and selling activity. Markets are also much faster in responding to new information, and to rare or unprecedented events.
These two mechanisms offer very different approaches to prediction. How might their relative accuracy be evaluated?
It just so happens that on the day of the debate I was at the 2024 Collective Intelligence conference, presenting a paper on the evaluation of forecasting mechanisms. This paper proposes and implements a test for the assessment of predictive accuracy whenever there exist models and markets that reference the same event, provided that the models are updated frequently. This is certainly the case with elections.
What we propose in the paper is quite straightforward. Any model can be represented by a virtual trader endowed with a budget, risk preferences, and beliefs that dogmatically track model forecasts. After each update, this hypothetical trader executes trades based on prevailing market prices and the portfolio inherited from the previous period. The trades result in an updated portfolio, and the process can be iterated until event realization. At that point one can look at the value of the portfolio and compute a rate of return on the initial budget.
A model that predicts better than the market should make a profit by taking advantage of overreaction and excess volatility. One that is worse than the market—perhaps because it is sluggish or cannot accomodate novel sources of valuable information—will make a loss. And more accurate models ought to deliver higher returns relative to less accurate ones, at least on average across a large number of events.
What would such a procedure have shown us over the past couple of days? Given the prices prevailing before the debate, the FiveThirtyEight model would have had a positive position in the Biden contract and would have sufferred a loss; the Silver model would have bet on Trump and secured a windfall gain. Both models would have made money on the Iowa Electronic Markets, where a popular vote contract is listed.
But much of this is based on sheer luck—had the debate been a disaster for Trump rather than Biden, the profitability of the virtual traders representing the models would have been reversed. A systematic comparison therefore requires a large number of events and model updates. We are now conducting such an analysis, and I will post our findings once the election has been decided.
Between now and then, I suspect that there will be plenty of other surprises.
The name FiveThirtyEight has long been associated with Nate Silver, but the digital property is now owned by ABC News and overseen by G. Elliot Morris, who administered the Economist model in 2020. Meanwhile Nate Silver has migrated to substack. To a first approximation, therefore, the Silver Bulletin model is descended from the original FiveThirtyEight, while the current FiveThirtyEight is descended from the old Economist model, which was based on a paper by Heidemanns, Gelman and Morris. As if this were not confusing enough, there is also a new Economist model.
How could both models have made money in the Iowa market?